作者 | 崔皓
审校 | 重楼
在AI开发场景中,很多开发者都有过这样的困扰:普通智能体只能处理简单的单步指令,面对多步骤、长周期的复杂任务时,要么杂乱无章,要么记忆过载,很难达到实际应用需求。而DeepAgents的出现,让智能体从“能执行”升级为“能组织”,成为具备统筹能力的“智能管理者”。更重要的是,借助LangChain和LangGraph工具,我们可以循序渐进地搭建一个属于自己的DeepAgents项目,从基础工具调用到进阶的子智能体协同,每一步都清晰可落地。
先搞懂:普通智能体的“痛点”,就是DeepAgents的“突破口”
在动手搭建项目前,我们先明确核心需求——为什么需要DeepAgents?普通智能体的三大痛点,正是我们搭建项目时需要重点解决的问题,也是DeepAgents的核心价值所在。
日常开发中,我们接触的普通智能体,处理“查天气”“转文本”这类单步任务时毫无压力,但如果让它完成“调研竞品并生成分析报告”这类复杂任务,就会暴露明显短板:
一是缺乏规划能力,拿到任务后“走一步看一步”,步骤混乱易遗漏,比如生成竞品报告时,一会儿查功能、一会儿查份额,无法形成有序流程;二是记忆过载,多步任务的中间结果、工具调用记录会撑满模型上下文,不仅增加Token成本,还会导致推理混乱(即“上下文污染”);三是能力单一,一个智能体包揽所有工作,既做调研又做编程,结果往往样样不精,且不同任务的数据相互干扰。
而我们要搭建的DeepAgents项目,核心就是解决这三大痛点,通过“任务规划+外部记忆+子智能体协同”的架构,让智能体具备“管理能力”。接下来,我们从基础到进阶,一步步完成项目搭建。
第一步:环境准备与基础搭建,实现简单工具调用
搭建DeepAgents项目的前提,是准备好基础开发环境,核心依赖LangChain和LangGraph——这两个工具能帮我们快速实现智能体的核心逻辑,无需从零开发。
首先执行安装命令,安装所需依赖(这是项目搭建的第一步,也是后续所有功能实现的基础):
安装完成后,我们从最基础的功能入手:实现一个能自主调用工具的文本处理智能体,这是DeepAgents项目的“入门操作”,也是后续复杂功能的基础。
核心思路是:用@tool装饰器将普通Python函数转换为LangChain可识别的工具,再通过create_agent函数,将LLM(大脑)、工具(能力)和系统提示词(行为准则)封装成可执行的智能体。关键代码如下:
比如,我们可以定义统计字数、转换大小写、提取关键词三个基础工具,用@tool装饰器标注后,LLM会自动识别工具的用途和参数。之后通过create_agent函数组装智能体,调用.invoke()方法即可运行——当用户输入“提取这段文字的关键词并转换为大写”时,智能体能自主选择对应的工具,完成任务后返回结果。
这一步的核心是掌握“工具定义”和“智能体构建”的基本逻辑:@tool装饰器的关键是清晰的文档字符串(docstring),它直接决定LLM能否正确调用工具;create_agent函数则是智能体的“组装器”,三大核心组件(LLM、Tools、System Prompt)缺一不可。
第二步:添加状态管理,让智能体拥有“记忆”
基础工具调用实现后,我们需要给智能体添加“记忆”——让它能记住任务列表和操作历史,这是实现复杂任务规划的关键。这一步,我们需要自定义智能体状态,解决普通智能体“记不住事”的痛点。
具体实现的核心,是继承LangGraph的基础AgentState,扩展自定义状态字段。我们可以定义一个状态类,继承AgentState(默认包含对话历史messages字段),再添加todos(任务列表)和files(虚拟文件系统,为后续进阶功能预留)两个字段。关键代码如下:
其中,todos字段用于存储任务列表,我们可以用字典列表的形式,每个字典包含任务描述(content)和任务状态(status,可选待处理、进行中、已完成);为了让任务状态能持续累积,我们会用Annotated标注字段,并搭配Reducer函数——当不同节点更新任务列表时,不会直接覆盖,而是合并新旧内容。
同时,我们需要实现两个核心工具:write_todos(创建/更新任务列表)和read_todos(读取当前任务列表)。write_todos工具通过InjectedState注入当前智能体状态,验证任务结构后,通过Command对象更新状态;read_todos工具则只读取状态,不作修改,直接返回任务列表。关键代码如下:
举个例子,当用户输入“调研MCP并总结”时,智能体会通过write_todos工具生成任务列表(“搜索MCP的定义”“整理MCP的核心功能”“总结MCP的应用场景”),并实时更新任务状态;执行过程中,智能体可以通过read_todos工具查看当前进度,确保任务有序推进。这一步,我们正式解决了普通智能体“缺乏规划”的痛点。
第三步:实现并行工具调用,提升多任务处理效率
当智能体拥有“记忆”后,我们可以进一步优化效率——实现并行工具调用,让智能体能够同时处理多个独立任务,解决普通智能体“串行执行效率低”的问题。
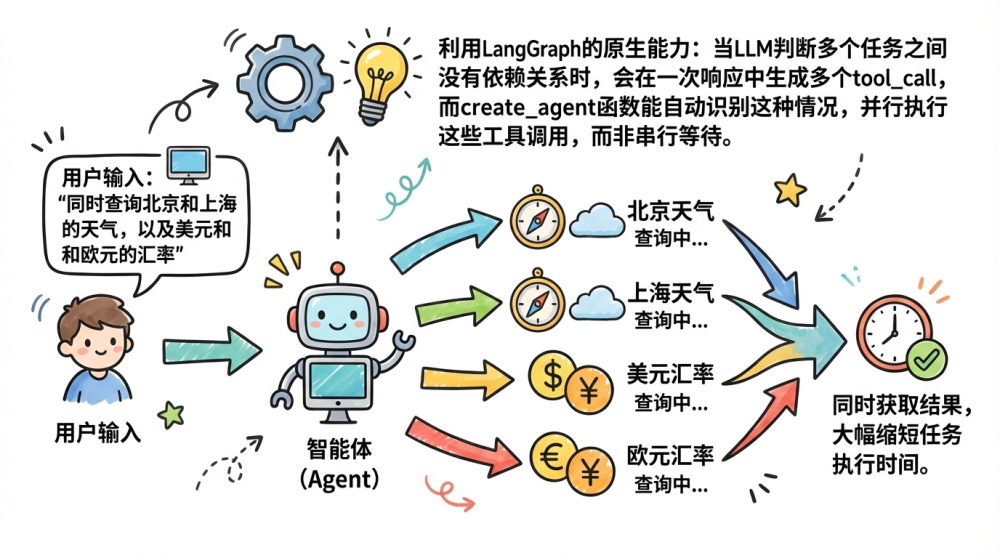
这一步的实现无需额外新增复杂工具,核心是利用LangGraph的原生能力:当LLM判断多个任务之间没有依赖关系时,会在一次响应中生成多个tool_call,而create_agent函数能自动识别这种情况,并行执行这些工具调用,而非串行等待。
比如,用户输入“同时查询北京和上海的天气,以及美元和欧元的汇率”,智能体无需先查完北京天气,再查上海天气,而是会并行发起四个查询请求,同时获取结果,大幅缩短任务执行时间。
这里需要注意的是,并行调用的关键的是LLM的决策能力——我们需要在系统提示词中明确指导模型,当遇到多个独立任务时,可发起多个工具调用。到这一步,我们的DeepAgents项目已经具备了“规划能力”和“高效执行能力”,能应对中等复杂度的任务。
第四步:引入虚拟文件系统,实现上下文卸载
随着任务复杂度提升,我们会遇到新的问题:处理大文件、长日志时,大量内容会撑爆LLM的上下文窗口,导致任务失败。这时候,我们需要给项目添加“虚拟文件系统”,实现上下文卸载,解决普通智能体“记忆过载”的痛点。
上下文卸载的核心逻辑很简单:不再把所有中间结果、大篇幅内容塞进对话上下文,而是将其写入虚拟文件系统,对话历史中只保留“文件路径+预览”,需要时再通过工具读取。这就像我们整理电脑文件,把大文件存入硬盘,桌面只留快捷方式,既节省空间,又能快速调取。
具体实现上,我们基于之前定义的DeepAgentState,完善files字段(字典类型,key为文件路径,value为文件内容),并实现三个核心工具:ls(列出所有文件路径)、read_file(分页读取文件内容)、write_file(写入/覆盖文件)。关键代码如下:
其中,read_file工具支持offset(起始行号)和limit(读取行数)参数,避免一次性读取大文件撑爆上下文;write_file工具通过Command对象更新文件系统,并在对话历史中追加文件更新提示;ls工具则用于查看当前所有文件,方便智能体和用户了解文件存储情况。
比如,我们处理大篇幅的调研数据时,智能体会通过write_file工具将数据写入“search_results.txt”文件,后续分析时,通过read_file工具分页读取内容,既避免了上下文过载,又能灵活处理大文件。这一步,我们彻底解决了普通智能体“记忆过载”的痛点,让项目能应对长周期、大内容的复杂任务。
第五步:添加子智能体委托,实现专业分工协同
当项目需要处理更复杂的任务(如行业研究、多领域调研)时,单一智能体的能力仍有局限。这时候,我们需要给项目添加“子智能体委托”功能,让主智能体能够分派任务,实现专业分工,解决普通智能体“能力单一”的痛点。
核心实现分为三步:定义子智能体配置、实现task工具、组装主监督智能体。
首先,用TypedDict定义SubAgent配置,相当于给子智能体编写“岗位说明书”,包含name(唯一标识,如“research-agent”)、description(功能描述,供主智能体决策)、prompt(系统提示词,指导子智能体工作)、tools(子智能体可使用的工具,如调研类子智能体只允许使用搜索工具)。关键代码如下:
在技术落地时,我们选择Tavily API作为搜索工具(专为AI设计,结果质量高,免费额度1000次/月,适合快速落地),并自定义行业研究框架,让智能体能够按“市场规模-发展历程-竞争格局-发展趋势”的维度,自动规划任务、调用工具、存储数据、生成报告。关键代码如下:
其次,通过create_task_tool函数,把子智能体变成可调用的工具。这个工具的核心作用是:主智能体调用task(description, subagent_type)时,会创建一个隔离的上下文(只包含任务描述和必要文件,不包含主智能体的完整对话历史),启动对应的子智能体执行任务,完成后将结果封装成ToolMessage汇回主智能体。
最后,通过create_supervisor_agent函数组装主智能体,将task工具和其他基础工具注入,主智能体负责制定战略、拆解任务、验收子智能体的结果,不直接执行具体操作。
举个例子,当主智能体需要完成“AI行业研究报告”时,会将任务拆分为“市场规模调研”“竞争格局分析”“发展趋势预测”三个子任务,分别委托给三个不同的子智能体(research-agent),三个子智能体并行执行,完成后将结果汇总给主智能体,主智能体再整合生成最终报告。这种模式既保证了专业性,又提升了效率。
此外,我们还可以添加一个think_tool工具,让主智能体在拿到子智能体结果后,显式记录思考过程,反思已掌握的信息、缺失的内容,规划下一步动作,确保任务整体可控。
项目落地:搭建AI行业研究助手,检验DeepAgents能力
当我们完成了以上五步搭建后,就可以将项目落地为一个实用的AI行业研究助手,检验DeepAgents的核心能力。这个助手适用于投资人、产品经理、求职者等各类人群,能帮助用户快速了解陌生行业。
整体架构如下:
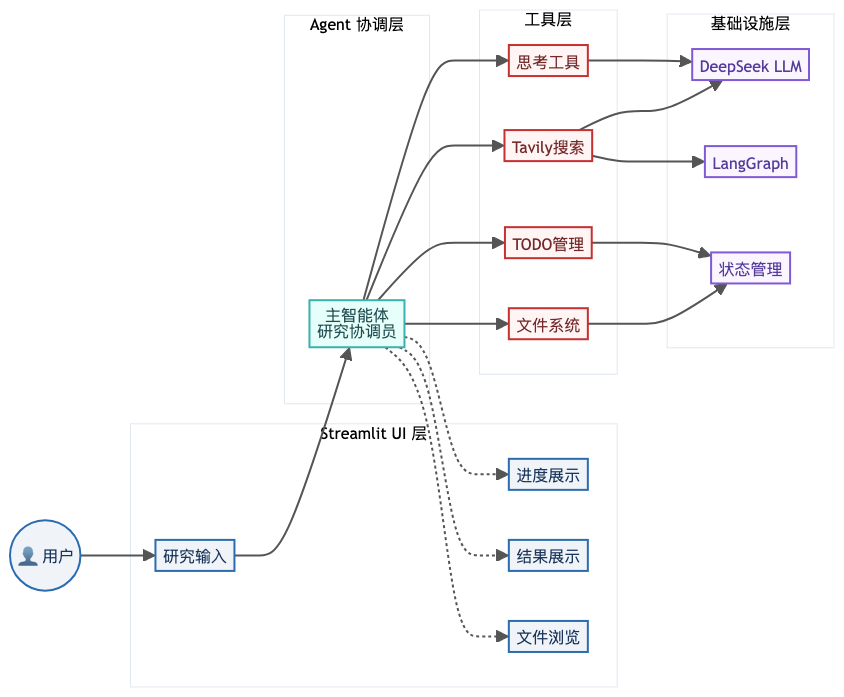
在技术落地时,我们选择Tavily API作为搜索工具(专为AI设计,结果质量高,免费额度1000次/月,适合快速落地),并自定义行业研究框架,让智能体能够按“市场规模-发展历程-竞争格局-发展趋势”的维度,自动规划任务、调用工具、存储数据、生成报告。
具体流程如下:用户输入目标行业(如“AI生成式内容行业”),主智能体通过write_todos工具生成调研任务列表;之后,主智能体委托子智能体,通过Tavily API搜索各维度信息,将搜索结果通过write_file工具存入虚拟文件系统;最后,主智能体整合文件中的信息,生成结构清晰的行业研究报告,全程无需用户手动干预。
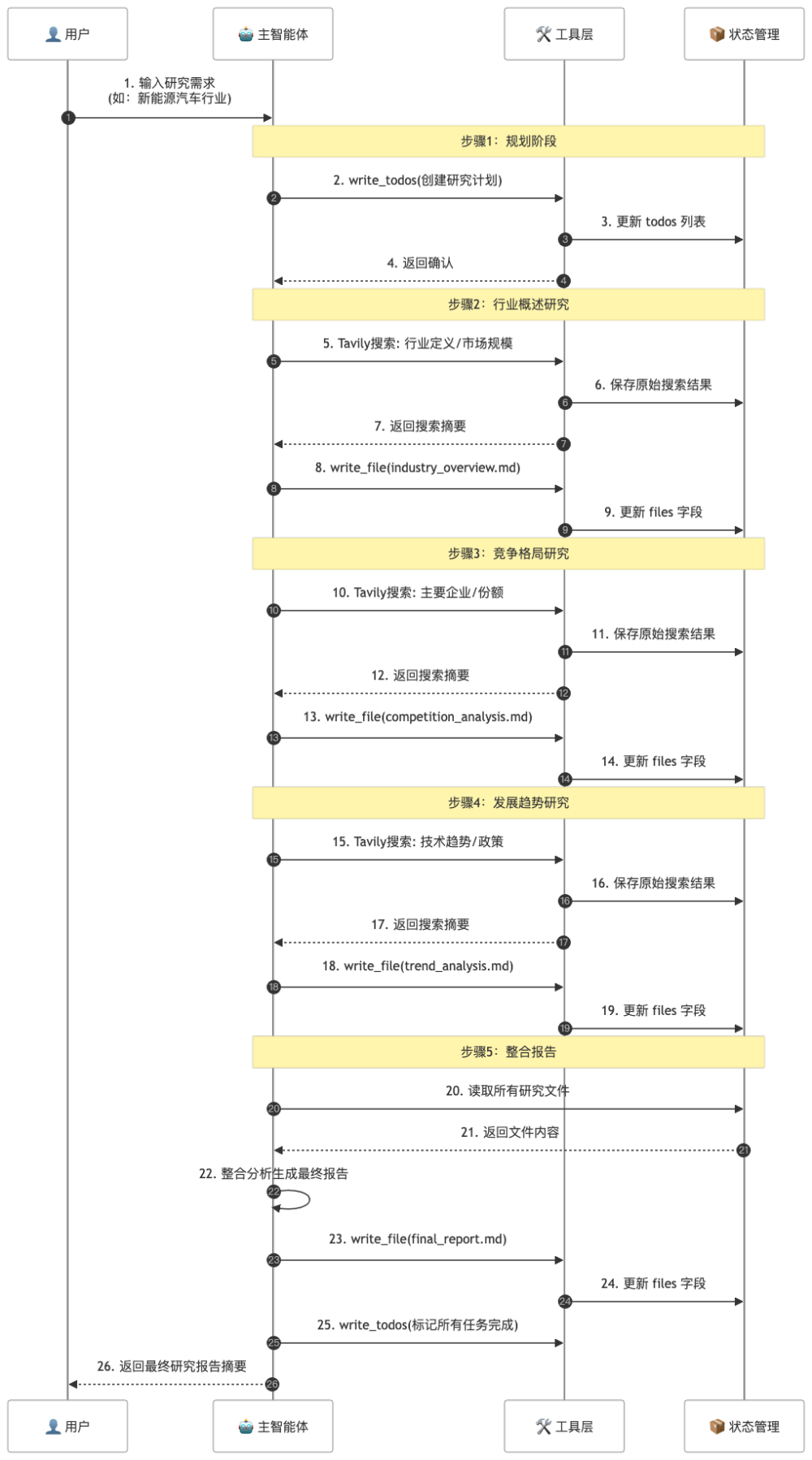
同时,我们可以添加流式输出功能,让用户实时看到任务进度和报告生成过程;通过状态同步函数,实现任务状态的实时更新,用户随时可以查看当前调研进度。
关键技术选型
组件 | 技术选择 | 选择理由 |
大模型 | DeepSeek | 中文能力强,推理成本低,适合复杂任务规划。 |
搜索引擎 | Tavily API | 专为 AI 设计的搜索 API,结果质量高,免费额度 1000 次/月,适合快速落地。 |
智能体框架 | LangGraph | 提供状态管理和流程控制,支持复杂工作流编排。 |
Web 框架 | Streamlit | 快速构建数据应用,自带响应式布局和组件系统。 |
状态管理 | LangGraph State | 通过状态注解实现跨工具的状态共享和持久化。 |
核心功能实现
智能体首先使用 write_todos 工具将复杂的研究任务分解为可执行的子任务:
每个任务都有明确的状态:pending(待处理)、in_progress(进行中)、completed(已完成),通过 update_todo_status 工具实时更新。这种结构化的任务管理方式,让用户能够清晰看到研究进度。
智能体根据任务列表,自动进行多维度的信息收集:
每次搜索后,智能体会使用 think 工具进行反思:
- “我找到了什么关键信息?”
- “这些信息是否足够回答用户的问题?”
- “还需要搜索哪些补充信息?”
这种反思-决策机制,确保了搜索的针对性和信息收集的完整性。
所有研究结果被实时存储在虚拟文件系统中,通过 write_file 工具写入:
这个虚拟文件系统有以下优点:
- 隔离性:每次研究都有独立的文件空间,避免数据混乱。
- 持久性:通过 LangGraph 的状态管理,文件在研究过程中持续保存。
- 可扩展:支持任意数量和类型的文件,适合存储不同维度的研究结果。
最后,主智能体整合所有文件中的信息,生成结构清晰的行业研究报告:
报告自动包含摘要、核心发现、详细分析、结论建议等部分,完全符合专业研究报告的格式要求。
关键代码解析
我们扩展了 LangGraph 的 AgentState,增加了任务列表和文件系统:
这里的 file_reducer 是一个自定义的合并函数,用于在状态更新时正确合并新旧文件:
通过 LangGraph 的状态注入机制,工具可以安全地访问和修改状态:
这种设计保证了工具之间的解耦和状态的统一管理。
智能体的创建过程清晰地体现了 DeepAgents 的设计理念:
项目亮点
这种实时反馈机制,大大提升了用户体验,让用户能够信任智能体的工作过程。
项目实现了完善的状态同步和容错机制:
这种设计保证了服务的稳定性,即使在 API 限流或网络故障的情况下,用户仍然可以得到模拟结果。
项目支持研究历史记录和报告导出:
项目价值与能力检验
验证了 DeepAgents 的几项核心能力:
能力维度 | 验证方式 | 结果体现 |
任务规划能力 | 自动生成结构化任务列表 | 从“新能源汽车”自动分解为概述、格局、趋势、报告四个任务 |
工具协调能力 | 多工具协同完成复杂任务 | 搜索→思考→存储→报告的完整流程自动化 |
状态管理能力 | 维护多维度中间状态 | 任务进度、文件系统、研究日志的一致性管理 |
错误恢复能力 | 异常情况下的降级服务 | API 故障时自动切换模拟模式,保证用户体验 |
用户体验 | 流式输出与实时反馈 | 用户能看到智能体的思考过程,建立信任感 |
总结:循序渐进,从入门到精通DeepAgents项目搭建
我们搭建DeepAgents项目的过程,正是解决普通智能体痛点的过程:从基础的工具调用,到状态管理实现任务规划,再到并行调用提升效率,最后通过虚拟文件系统和子智能体委托,实现复杂任务的高效处理,每一步都循序渐进、可落地。
整个项目的核心逻辑,是让智能体从“被动执行”升级为“主动管理”——通过“规划-分解-委托-整合”的闭环架构,让智能体能够调度资源、管理记忆、分工协作。对于开发者而言,借助LangChain和LangGraph,我们无需从零开发核心逻辑,只需按步骤完善功能,就能快速搭建出具备DeepAgents能力的智能体。
未来,我们还可以基于这个项目进一步优化:将虚拟文件系统与持久化存储(如Postgres)结合,实现跨会话的长期记忆;优化子智能体的配置,支持更多专业场景;添加UI界面,让非技术用户也能轻松使用。相信随着技术的迭代,DeepAgents将在更多场景中落地,成为我们工作中的“智能伙伴”。
作者介绍
崔皓,51CTO社区编辑,资深架构师,拥有18年的软件开发和架构经验,10年分布式架构经验。