摩尔线程发布大模型训练仿真工具SimuMax v1.0:显存误差仅1%
9月11日快科技消息,摩尔线程正式发布并开源大模型分布式训练仿真工具SimuMax v1.0,在显存和性能仿真精度上实现了突破性提升,同时引入多项关键功能,进一步增强了模型兼容性、灵活性。
SimuMax是一款专为大语言模型(LLM)分布式训练负载设计的仿真模拟工具,可为从单卡到万卡集群提供仿真支持。
它无需实际执行完整训练过程,即可高精度模拟训练中的显存使用和性能表现,帮助用户提前了解训练效率,优化计算效能。
基于静态分析模型,摩尔线程自研的SimuMax通过结合成本模型、内存模型和屋顶模型,实现对训练过程的精准仿真。

该工具支持多种主流分布式并行策略与优化技术,适用于以下多种应用场景:
1、并行策略:
数据并行(DP)、张量并行(TP)、序列并行(SP)、流水线并行(PP)、专家并行(EP)
2、优化技术:
ZeRO-1、完整重计算、选择性重计算、融合内核等。
3、适用对象:
希望寻找最优训练策略以提升效率的用户;
从事框架或大模型算法开发的工程师,用于优化与调试;
芯片制造商,用于性能预测与硬件设计辅助。
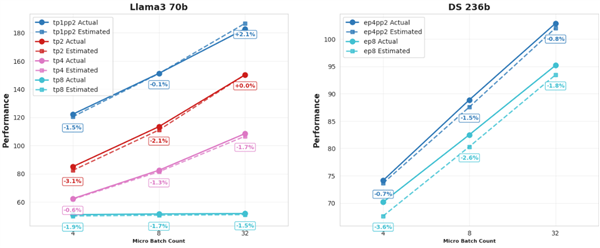
SimuMax 1.0最显著的更新在于其仿真精度的大幅提升,为用户提供更可靠的分析结果。
针对Dense和MoE(混合专家)模型,显存估计误差稳定控制在1%以内。
经测试,在多个主流GPU上,目前最优性能估计误差持续低于4%。
此外,SimuMax 1.0还引入了多项新特性,支持更广泛的模型结构和高效率训练需求:
MLA支持:
新增对MLA模型架构的支持;
流水线并行(PP)增强:
支持对首阶段和末阶段层的细粒度控制,优化模型分片策略;
MoE灵活性提升:
在混合专家(MoE)模型中支持自定义Dense层,为模型设计提供了更大的灵活性。
Megatron兼容:
提供简化的模型迁移流程,可轻松转换和分析基于Megatron框架的模型,提升与现有生态的互操作性。
重计算策略优化:
实现更细粒度的选择性重计算,支持更精准的内存和计算资源权衡。
全面的效率分析:
新增对不同张量形状与内存布局下计算效率与利用率的评估功能。
以上就是全部内容,喜欢的话记得收藏本站,我们将持续为您带来更多精彩内容。